
Cách phát hiện và xử lý VPS bị chậm vì noisy neighbor
Sơ đồ trang
VPS (Virtual Private Server) về bản chất là một phần của máy chủ vật lý. Bạn vẫn phải chia sẻ CPU time, storage queues và network với các VPS khác chung máy chủ.
Các triệu chứng như load average cao nhưng CPU usage thấp thường cho thấy có sự tranh chấp tài nguyên—CPU steal time hoặc I/O bị block (iowait).
Hãy đo lường, chứng minh, rồi chuyển gói hoặc chọn gói dịch vụ được thiết kế để tránh bị tình trạng này.
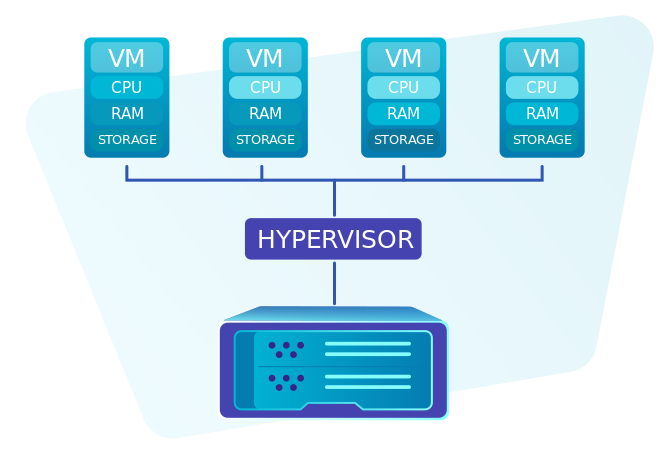
Hiểu lầm phổ biến về VPS
Nhiều người mua VPS với kỳ vọng có “tài nguyên riêng biệt”. Bạn có thể thực sự nhận được RAM riêng và một số lượng vCPU nhất định, nhưng chu kỳ CPU, hàng đợi storage, và đôi khi cả băng thông mạng vẫn được chia sẻ.
Cách Hypervisor hoạt động:
Hypervisor (phần mềm quản lý các VMs) không thể “nhân đôi” CPU vật lý. Thay vào đó, nó dùng kỹ thuật time-slicing—chia nhỏ thời gian CPU thành các khung hình (time slice) và phân phối cho từng VM theo lượt.
Tưởng tượng như một nhà hàng có 4 đầu bếp (4 cores vật lý), nhưng phải phục vụ 20 bàn (20 VMs). Mỗi bàn nghĩ mình có “đầu bếp riêng” (vCPU), nhưng thực tế 20 bàn này phải chia sẻ 4 đầu bếp. Khi nhiều bàn cùng gọi món, một số bàn phải chờ đợi—đó chính là steal time.
Bài viết liên quan
Ngành công nghiệp thậm chí còn có tên gọi cho hiện tượng này: noisy neighbor effect—một tenant khác trên cùng host chiếm dụng CPU, disk hoặc network và instance của bạn bị ảnh hưởng.
Triệu chứng thực tế: “Load average 5.0+, nhưng không có gì?”
Bạn chạy top và iotop nhưng thấy rất ít hoạt động CPU hoặc disk, thế nhưng uptime hiển thị load averages như 5.22, 5.10, 5.19.
Trông có vẻ nghịch lý—cho đến khi bạn nhớ lại cách Linux tính toán load average.
Linux load average đếm gì?
Load average là con số trung bình của các tiến trình đang chờ được xử lý trong hệ thống. Cụ thể, Linux đếm:
- Các task ở trạng thái R (Runnable/Running)
- Nghĩa: Tiến trình đang chạy HOẶC đang chờ đến lượt để chạy trên CPU
- Ví dụ: Một script PHP đang xử lý dữ liệu, hoặc đang xếp hàng chờ CPU rảnh
- Các task ở trạng thái D (Uninterruptible Sleep)
- Nghĩa: Tiến trình đang chờ I/O hoàn thành và KHÔNG THỂ bị ngắt
- Ví dụ: WordPress đang chờ đọc file từ disk, MySQL đang chờ ghi dữ liệu
- Đặc điểm: Bạn không thể kill được process này bằng
kill -9
Tại sao có 3 con số trong load average?
Khi chạy lệnh uptime, bạn thấy: load average: 5.22, 5.10, 5.19
- 5.22 = load average trong 1 phút vừa qua
- 5.10 = load average trong 5 phút vừa qua
- 5.19 = load average trong 15 phút vừa qua
Hiểu đơn giản:
- Nếu bạn có 4 vCPUs, load average lý tưởng là ≤ 4.0
- Load = 4.0 nghĩa hệ thống đang sử dụng 100% công suất
- Load = 8.0 nghĩa có 8 task đang chờ, nhưng chỉ có 4 CPU → hệ thống quá tải gấp đôi
Vậy tại sao load cao nhưng CPU lại nhàn rỗi?
Vì load average không CHỈ đếm task đang dùng CPU, mà còn đếm cả task đang chờ I/O (trạng thái D).
Ví dụ thực tế:
- Bạn có 100 request WordPress
- Mỗi request phải đọc file từ disk chậm
- 95 request đang ở trạng thái D (chờ I/O)
- 5 request đang dùng CPU
→ Load average = 100, nhưng CPU usage chỉ ~5%
Kết luận: Load cao + %us/%sy thấp = Các thread bị block bởi I/O (storage chậm) HOẶC bị hypervisor “bỏ đói” (steal time cao). Cả hai đều phổ biến trên shared hosts.
Hai nghi phạm thường gặp
1) Tranh chấp CPU → steal time
Khi hypervisor ưu tiên các VMs khác, vCPU của bạn sẵn sàng nhưng không thể chạy. Các công cụ thể hiện điều này qua steal time (%st). Thực tế, bạn yêu cầu CPU nhưng không nhận được.
Định nghĩa: Steal time là phần trăm thời gian vCPU của bạn bị chờ đợi không tự nguyện vì hypervisor đang chạy cho người khác. Có thể đo bằng top, vmstat, mpstat, iostat.
Nguyên tắc đơn giản: Nếu %st > 10% trong khoảng 20 phút, bạn đang bị ảnh hưởng bởi tranh chấp; hãy migrate hoặc đổi gói dịch vụ.
2) Tranh chấp Storage → iowait
iowait là thời gian CPU nhàn rỗi nhưng đang chờ I/O hoàn thành—điển hình khi storage backend hoặc queue bị bão hòa (do chia sẻ). Điều này đẩy các thread vào trạng thái D và làm tăng load average ngay cả khi iotop trông yên tĩnh tại thời điểm đó.
Cách khắc phục sự cố tối thiểu, có thể lặp lại (copy/paste)
Cài đặt các công cụ cơ bản (RHEL/Alma/Rocky):
sudo dnf install --assumeyes sysstat
Với Ubuntu/Debian:
sudo apt-get update && sudo apt-get install -y sysstat
Snapshot CPU/steal mỗi giây:
# iostat: Chỉ xem CPU; cột cuối cùng là "steal"
iostat -c 1 30
# Hoặc phân tích chi tiết từng CPU (từ sysstat)
mpstat -P ALL 1 30
# Kiểm tra nhanh với top
{ uptime; echo; top -bn1 | head -n 20; } 2>&1
Tại sao cách này hiệu quả: iostat/mpstat cho thấy %st (steal). Nếu nó cao liên tục, bạn đang bị thiếu CPU do hàng xóm. top xác nhận load và cũng hiển thị %st.
Kiểm tra xem load có phải do I/O không:
# Thống kê thiết bị mở rộng; tìm await/svctm/util cao
iostat -x 1 10
%iowait cao + ứng dụng phản hồi chậm + nhiều thread ở trạng thái D = tranh chấp storage. Nhớ rằng: load có thể tăng vọt chỉ từ các task bị block bởi I/O.
Kiểm tra nhanh “Lỗi do chúng ta hay do host?”
- %st > ~10% trong thời gian dài → Tranh chấp CPU ở host
- Nhiều thread trạng thái D, load tăng, phản hồi chậm → Tranh chấp storage queue
- top hiển thị %us/%sy thấp, nhưng uptime cao → Không phải CPU-bound, có thể là I/O hoặc steal
Đếm số thread ở trạng thái D:
ps -eo state= | awk '$1=="D"{c++} END{print c+0}'
Kiểm tra chi tiết với perf (nâng cao)
Nếu bạn muốn phân tích sâu hơn về scheduler wait time:
# Ghi lại scheduler events trong 30 giây
sudo perf sched record -a -- sleep 30
# Xem tổng hợp thời gian chờ
sudo perf sched timehist --summary --state
Giải thích: Lệnh này sẽ cho bạn biết mỗi task đã chờ bao lâu trong queue trước khi được CPU xử lý. Nếu thấy delay hàng chục milliseconds (thay vì sub-millisecond bình thường), đó là dấu hiệu rõ ràng của CPU contention.
Case study thực tế
Case 1: WordPress site phản hồi chậm
Triệu chứng ban đầu:
- Load average dao động 5.0-6.0 trên VPS 2 vCPU
topcho thấy CPU usage chỉ ~20%- Website WordPress phản hồi chậm, đôi khi timeout
Phân tích:
$ iostat -c 1 30
avg-cpu: %user %nice %system %iowait %steal %idle
8.2% 0.0% 5.1% 42.3% 18.5% 25.9%
Phát hiện:
- %iowait = 42.3% → Storage bị nghẽn nghiêm trọng
- %steal = 18.5% → Đồng thời bị tranh chấp CPU
- Kết hợp hai yếu tố này khiến load tăng cao
Kiểm tra thêm:
$ iostat -x 1 10
Device r/s w/s await svctm %util
vda 45.2 89.3 285.4 12.1 98.5%
Giá trị await (thời gian chờ trung bình) = 285ms là cực kỳ cao. Bình thường SSD nên < 10ms.
Giải pháp:
- Yêu cầu provider migrate sang host khác
- Sau khi migrate:
- Load giảm xuống 0.5-1.0
- %steal < 2%
- %iowait < 5%
- Website phản hồi nhanh trở lại
Bài học: Đây là case điển hình của “noisy neighbor”—cùng một VM, nhưng chuyển sang host vật lý khác (ít tải hơn) thì vấn đề biến mất ngay lập tức.
Case 2: RabbitMQ cluster mất quorum
Bối cảnh: Một công ty self-hosting RabbitMQ cluster trên VPS. Vào sáng Boxing Day, hệ thống gặp sự cố nghiêm trọng.
Triệu chứng:
- Backlog messages tích tụ hàng triệu
- RabbitMQ cluster báo mất quorum (không thể elect leader)
- Metrics trông bình thường (RAM OK, network OK)
- Heartbeat giữa các nodes liên tục fail
Kiểm tra:
$ top
%Cpu(s): 15.2 us, 8.1 sy, 0.0 ni, 76.7 id, 0.0 wa, 0.0 hi, 0.0 si, 73.5 st
Phát hiện then chốt:
- %st = 73.5% → Steal time cực kỳ cao!
- Điều này nghĩa: 73.5% thời gian, vCPU sẵn sàng chạy nhưng hypervisor không cấp CPU
- Kết quả: RabbitMQ nodes không thể gửi heartbeat kịp thời → cluster nghĩ các node đã chết
Giải pháp:
- Liên hệ provider khẩn cấp
- Provider xác nhận host đang oversubscribed nghiêm trọng
- Live migrate sang host khác
- Cluster tự recovery sau khi %steal giảm xuống < 5%
Bài học: Với distributed systems (như RabbitMQ, Elasticsearch, Kafka), steal time cao không chỉ làm chậm mà còn có thể phá vỡ consensus protocols. Những hệ thống này cần CPU với latency thấp và ổn định.
Case 3: Database queries timeout ngẫu nhiên
Triệu chứng:
- MySQL queries thỉnh thoảng timeout
- Không có slow query log nào
- Query giống hệt đôi khi chạy nhanh (50ms), đôi khi timeout (30s+)
Phân tích:
$ mpstat -P ALL 1 30
09:15:22 AM CPU %usr %sys %iowait %steal %idle
09:15:23 AM 0 25.0 10.2 3.1 45.2 16.5
09:15:23 AM 1 22.1 8.9 2.8 52.3 14.0
Phát hiện:
- %steal dao động 40-60% theo từng giây
- Pattern: Mỗi vài phút lại có đợt spike steal time
- Đúng lúc spike, queries timeout
Nguyên nhân: Một VPS hàng xóm đang chạy batch job theo schedule (có thể backup, hoặc data processing). Khi batch job chạy → chiếm CPU → VPS của bạn bị steal.
Giải pháp:
- Ngắn hạn: Increase query timeout + retry logic
- Dài hạn: Upgrade lên Dedicated CPU plan
- Best practice: Set up monitoring alert khi %steal > 15% trong 5 phút
Bài học: Steal time không phải lúc nào cũng steady. Nó có thể bursty (đột ngột tăng). Cần monitor theo time series, không chỉ nhìn snapshot.
Cần ticket hỏi nhà cung cấp
Hỏi nhà cung cấp
- Kiểm tra tranh chấp host và migrate bạn sang node yên tĩnh hơn. Một số nền tảng hỗ trợ live migration (gián đoạn tối thiểu); một số khác yêu cầu cold migration (shutdown trong quá trình chuyển).
- Chuyển sang Dedicated CPU / pinned vCPU plans nếu workload của bạn nhạy cảm với latency jitter hoặc cần CPU liên tục. Shared-CPU SKU chấp nhận một số steal; Dedicated SKU giảm thiểu nó.
Những gì bạn có thể tự thay đổi
1. Tách I/O khỏi request paths
- Xếp hàng ghi (queue writes)
- Bật các lớp caching (FastCGI cache, Redis page cache, hoặc Varnish phía trước application)
- Đảm bảo gzip/HTTP/3 không đẩy công việc blocking vào hot paths
2. Tối ưu storage
- Ưu tiên local NVMe nếu có
- Nếu phải dùng networked volumes, benchmark và tune (I/O scheduler, queue depths)
- Xem xét RAID cấu hình phù hợp cho workload của bạn
3. Giảm chattiness
- Batch DB writes (gộp nhiều ghi thành một)
- Tắt verbose access logs cho các endpoint có RPS cao
- Sử dụng async workers cho các tác vụ nặng
4. Quan sát, sau đó autoscale (hoặc scale up)
- Nếu workload thực sự CPU-bound, thêm vCPUs
- Chuyển tiers để tách các nodes, tránh noisy neighbors ở một tier block các tier khác
5. Tối ưu application (đặc biệt với WordPress/PHP)
- Sử dụng object caching (Redis/Memcached)
- Bật OPcache cho PHP
- Tối ưu database queries (indexes, query optimization)
- Sử dụng CDN cho static assets
- Lazy load images và defer non-critical JavaScript
- Giảm số lượng plugins, chỉ giữ những cái cần thiết
FAQ: Những hiểu lầm phổ biến
“iotop nói không có gì xảy ra, vậy không thể là I/O.”
iotop hiển thị I/O hiện tại theo process, không phải toàn bộ storage fabric’s queueing. Các thread của bạn có thể bị block chờ I/O hoàn thành ngay cả khi utilization tạm thời trông thấp. Kiểm tra iostat -x và số lượng D-state.
“Load cao có nghĩa là CPU bị chiếm.”
Trên Linux, load cũng đếm trạng thái D (I/O wait). Vì vậy, load cao + %us/%sy thấp là hoàn toàn nhất quán.
“VPS của tôi có 4 vCPUs, vậy nó là dedicated CPU.”
Không. vCPUs là time-slices. Trừ khi bạn đang ở gói Dedicated CPU/pinned SKU, steal time có thể và sẽ xảy ra.
“Tôi trả tiền cho VPS, không phải shared hosting.”
VPS cung cấp isolation tốt hơn về memory và process, nhưng vẫn chia sẻ phần cứng vật lý. Sự khác biệt chính là độ isolation, không phải việc loại bỏ hoàn toàn sự chia sẻ.
“Steal time chỉ xảy ra trên VPS rẻ tiền.”
Không đúng. Ngay cả các cloud providers lớn như AWS, GCP, Azure cũng có shared-CPU instances. Sự khác biệt là họ có SLA rõ ràng và tools để monitor/alert tốt hơn.
“Nếu CPU usage thấp thì hệ thống không thiếu tài nguyên.”
Sai. CPU usage chỉ đo những gì VM được phép chạy. Nếu hypervisor không cấp CPU cycles (steal time), usage sẽ thấp nhưng application vẫn chậm.
Nhà cung cấp hiểu ngôn ngữ %steal, %iowait và D-state. Bạn sẽ nhận được hành động nhanh hơn.
So sánh các loại instance
| Feature | Shared CPU | Burstable (t3) | Dedicated CPU | Bare Metal |
|---|---|---|---|---|
| vCPU scheduling | Time-sliced | Baseline + burst | Pinned cores | Physical cores |
| Steal time | 5-20% typical | 0-80% (depends on credits) | < 2% | 0% |
| Price (relative) | 1x | 1-1.5x | 2-3x | 5-10x |
| Use case | Dev/test, batch | Low traffic websites | Production APIs | High-performance computing |
| Predictable latency | ✗ | ✗ | ✓ | ✓ |
| SLA | Uptime only | Uptime only | Performance SLA | Performance SLA |
Kết luận
- VPS là shared hosting với isolation tốt hơn. Tranh chấp vẫn tồn tại.
- Load cao với CPU thấp thường có nghĩa là I/O wait hoặc steal. Đo cả hai.
- %st hoặc blocked I/O liên tục → migrate hosts hoặc chuyển sang Dedicated CPU / storage tốt hơn.
- Thiết kế stack của bạn (caching, async, batching) để chịu đựng được latency variance.
- Monitor liên tục để phát hiện vấn đề sớm và có data khi cần escalate với provider.
- Hiểu rõ SLA của bạn – không phải mọi gói VPS đều đảm bảo performance, một số chỉ đảm bảo uptime.
- CPU credits là con dao hai lưỡi – Burstable instances tốt cho workload có traffic không đều, nhưng nguy hiểm cho production services.
- Noisy neighbor không phải lỗi của bạn – Nhưng bạn có trách nhiệm detect và escalate sớm.






